This is another large release. This is the first stable release with a complete UTF-8 based backend. I’m still calling it pre-alpha because I’ve only really run it on Linux (quite extensively).
In this Release:
- UTF-8 Backend (see below for tech details)
- New RTF loader (less complete, but more robust)
- New DOCX loader (incomplete, but not bad)
Bug Fixes:
- Yeah, a lot of corner-cases from moving to UTF-8
- Actual UTF-8 data entry from keyboard has not been tested, just copy from web to WordTsar.
- I reset the build number for this release. Don’t ask me why, I can’t remember.
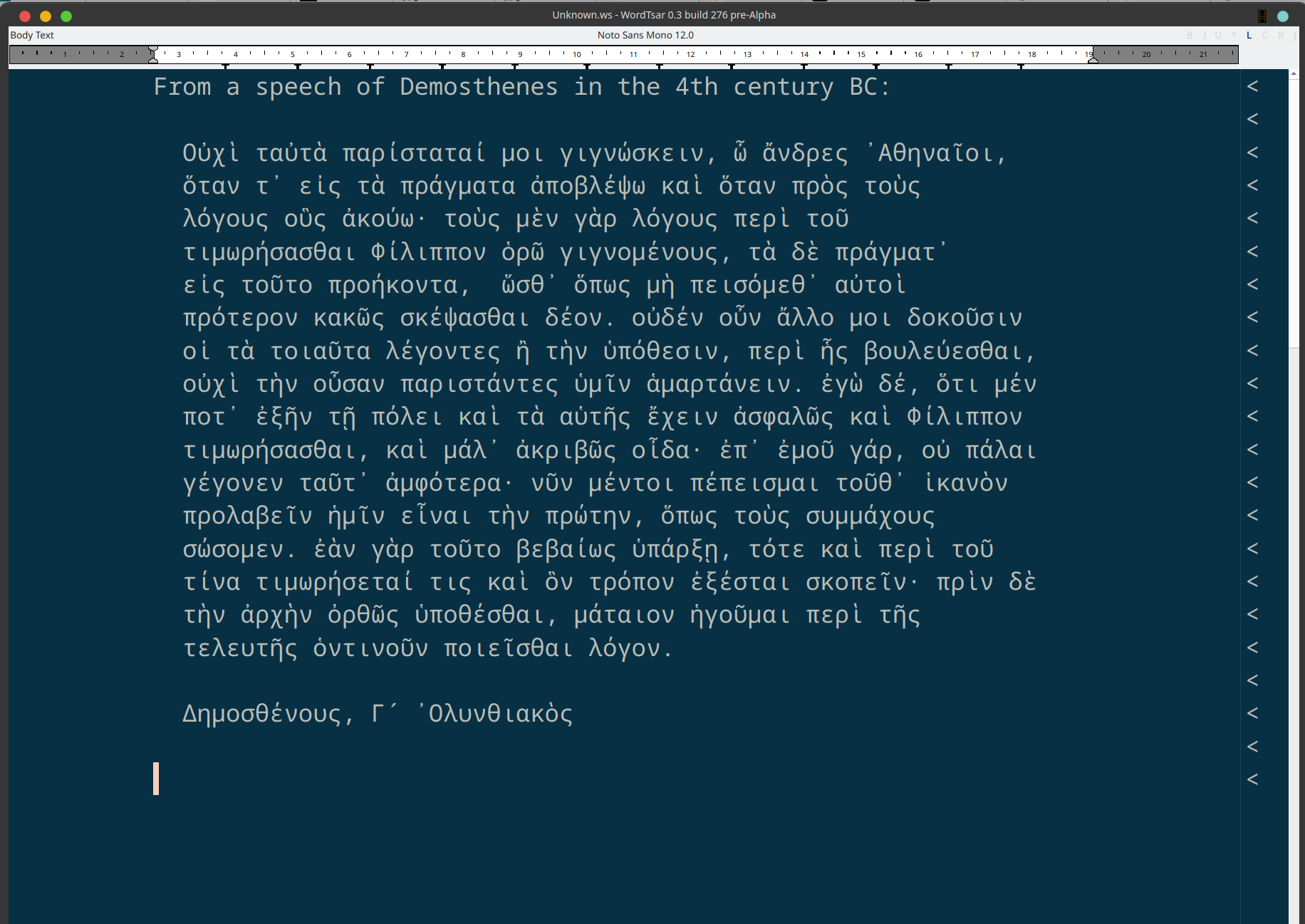
Tech Details
Every version of WordTsar has been using a gapbuffer for it’s underlying document buffer. Adding UTF-8 support added created issues with the single buffer issue. We now use a plain buffer per paragraph, and have seen some slow downs because of it. We’ve added caching that should get around that.
Carat movement is all grapheme based. If a grapheme is made up of multiple codepoints, deleting will remove the entire grapheme.
The File save and load routines don’t fully understand UTF-8 yet. Wordstar file save and load most likely never will.
I’m a Canadian English writer. All of this UTF-8 stuff needs more testing than I was able to give it.